A practical guide to what the Artificial Intelligence Infrastructure Workshop PDF teaches, why it matters, and how to build production-grade AI infrastructure.
The Artificial Intelligence Infrastructure Workshop PDF

If you have searched for the Artificial Intelligence Infrastructure Workshop PDF, you are almost certainly trying to do one of two things: learn how real AI systems are built and run behind the scenes, or find a structured, hands-on resource you can work through at your own pace. This guide explains exactly what such a workshop covers, why infrastructure is the part of AI that quietly decides whether a model succeeds or fails in production, and how to extract maximum value from any PDF or course bearing this title.
We have built and reviewed AI systems for businesses ranging from early-stage startups to data-heavy enterprises, and the single most common reason projects stall is not the model. It is the infrastructure underneath it. This article gives you the practitioner's view that most downloadable PDFs only hint at.
Quick Answer: The Artificial Intelligence Infrastructure Workshop PDF is a hands-on guide teaching how to design, deploy, and scale the compute, storage, data pipelines, and MLOps systems that power AI models. It covers GPUs, containers, orchestration, and monitoring so models run reliably and cost-effectively in production.
What Is AI Infrastructure?
AI infrastructure is the complete stack of hardware, software, data systems, and operational tooling required to train, deploy, and run machine learning models at scale. It is the foundation that turns experimental notebooks into dependable products serving real users.
Most beginners assume AI is mostly about algorithms. In practice, a typical production AI system spends far more engineering effort on data pipelines, deployment, and monitoring than on the model itself. A workshop PDF worth your time treats infrastructure as a first-class discipline rather than an afterthought, because that is where most real-world value and risk live.
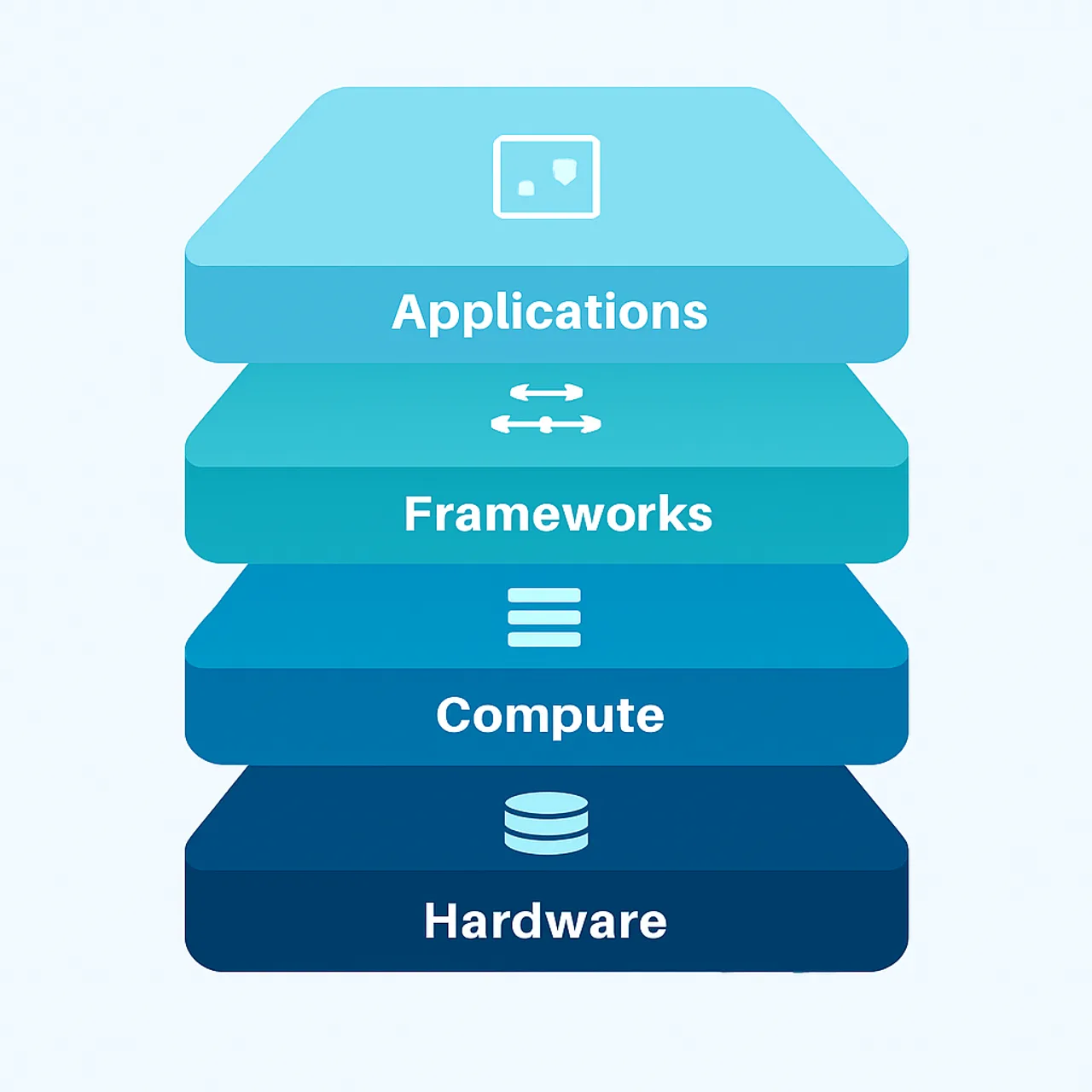
The core layers of AI infrastructure include:
- Compute — CPUs, GPUs, and increasingly specialized accelerators like TPUs.
- Storage — object stores, data lakes, and feature stores for training data.
- Orchestration — containers, Kubernetes, and schedulers that manage workloads.
- MLOps tooling — pipelines for training, versioning, deployment, and monitoring.
- Serving — APIs and inference endpoints that deliver predictions to applications.
Why an AI Infrastructure Workshop Matters
A structured workshop matters because it sequences knowledge in the order you actually need it. Random tutorials teach isolated tools; a good workshop teaches how those tools connect into a system. That distinction is the difference between knowing what Docker is and knowing how to package a model, deploy it on a cluster, and roll back safely when an update degrades accuracy.
According to Gartner, a large share of AI projects historically failed to move from prototype to production, and weak infrastructure and operationalization are repeatedly cited among the leading causes. A workshop format directly targets this gap by forcing you to build an end-to-end system, not just a model in a notebook.
For teams that lack in-house specialists, partnering with experienced engineering providers such as ZoneTechify or WebPeak can shorten the learning curve dramatically, turning months of trial and error into a guided rollout.
What the Artificial Intelligence Infrastructure Workshop PDF Typically Covers
A comprehensive workshop PDF is usually organized into progressive modules. While titles vary by publisher, the strongest versions cover the following ground.
1. Foundations of Compute and Hardware
This module explains why GPUs dominate AI training. GPUs perform thousands of parallel matrix operations simultaneously, making them dramatically faster than CPUs for neural network workloads. You learn how to choose between cloud GPUs and on-premise hardware, how to read memory and throughput specifications, and how to avoid the classic mistake of over-provisioning expensive accelerators you only use a fraction of the time.

2. Data Pipelines and Storage
Data is the fuel of AI, and this section teaches you to build reliable pipelines that ingest, clean, transform, and version data. You explore the difference between data lakes and feature stores, and why reproducibility — the ability to recreate the exact dataset used to train a model — is non-negotiable for trustworthy systems.
3. Containers and Orchestration
Here the workshop introduces Docker for packaging models with their dependencies and Kubernetes for orchestrating those containers across machines. Containerization is the practice of bundling an application and everything it needs to run into a single portable unit. This guarantees a model behaves identically on a laptop and in production, eliminating the "it worked on my machine" failure that derails so many deployments.
4. MLOps and Automation
MLOps applies DevOps principles to machine learning. This module covers continuous training, automated testing of model quality, and deployment pipelines that ship updates safely. The goal is repeatability: any team member should be able to retrain and redeploy a model with a single command instead of a fragile manual process.
5. Model Deployment and Scaling
This section teaches how to serve models through APIs, handle traffic spikes with autoscaling, and choose between real-time inference and batch processing. You learn techniques like model quantization and caching that reduce latency and cost without sacrificing accuracy.
6. Monitoring, Cost, and Governance
The final modules address what happens after launch: detecting model drift, tracking spend, securing endpoints, and maintaining compliance. These topics separate hobby projects from production systems that businesses can trust.
Cloud vs On-Premise AI Infrastructure: A Comparison
One of the most practical decisions a workshop helps you make is where to run your workloads. The table below summarizes the trade-offs.
| Factor | Cloud Infrastructure | On-Premise Infrastructure |
|---|---|---|
| Upfront cost | Low | High |
| Scalability | Instant and elastic | Limited by hardware |
| Maintenance | Managed by provider | Your team's responsibility |
| Data control | Shared environment | Full control |
| Best for | Startups, variable workloads | Strict compliance, steady high usage |
| Time to start | Minutes | Weeks to months |
Most organizations begin in the cloud for speed and flexibility, then consider hybrid or on-premise setups only when scale or regulation justifies the investment.
How to Get the Most From the Workshop PDF
Reading a PDF passively teaches very little about infrastructure. Follow these steps to convert the material into real, durable skill.
- Build along, do not just read. Spin up a free-tier cloud account and deploy a small model end to end.
- Recreate every diagram as working code. If the PDF shows a pipeline, build that pipeline yourself.
- Break things deliberately. Kill a container, exhaust memory, or corrupt a dataset to learn how systems fail and recover.
- Track your costs daily. Cost awareness is a core infrastructure skill the best workshops emphasize.
- Document your setup. Writing your own runbook cements understanding far better than re-reading the PDF.
If you would rather have experts implement production infrastructure for you, explore professional artificial intelligence services that handle architecture, deployment, and scaling end to end.

Common Mistakes the Workshop Helps You Avoid
From real-world experience, these are the errors that quietly destroy AI projects, and a good workshop inoculates you against each:
- Treating infrastructure as an afterthought instead of designing it from day one.
- Ignoring reproducibility, making it impossible to debug or audit models later.
- Over-provisioning GPUs and burning budget on idle hardware.
- Skipping monitoring, so model drift silently erodes accuracy for months.
- Manual deployments that are slow, error-prone, and impossible to roll back cleanly.
The Future of AI Infrastructure
AI infrastructure is moving toward greater automation, efficiency, and decentralization. Edge inference is pushing models closer to users for lower latency, while serverless GPU platforms are removing the need to manage clusters at all. As models grow larger, techniques like distributed training and model compression are becoming standard infrastructure skills rather than niche specialties.
The practitioners who thrive will be those who understand the full stack — not just how to train a model, but how to run it reliably and affordably for millions of requests. That holistic view is exactly what a quality workshop PDF aims to build.

Key Takeaways
- AI infrastructure is the hardware, software, data, and operational stack that runs AI models in production — it decides success more often than the model itself.
- A strong workshop PDF covers compute, data pipelines, containers, MLOps, deployment, and monitoring as one connected system.
- Many AI projects fail to reach production, and weak infrastructure and operationalization are leading causes.
- GPUs accelerate training through massive parallelism, but over-provisioning them wastes budget.
- Reproducibility, automation, and monitoring are the non-negotiable pillars of trustworthy AI systems.
- Build along with the PDF, break things on purpose, and track costs to truly learn infrastructure.
Frequently Asked Questions (FAQ)
What is the Artificial Intelligence Infrastructure Workshop PDF about?
It is a hands-on learning resource that teaches how to design, deploy, and scale the systems that power AI models. It typically covers compute, GPUs, data pipelines, containers, MLOps, deployment, and monitoring, helping you move models from experimental notebooks to reliable production environments that serve real users.
Do I need coding experience to use an AI infrastructure workshop?
Basic programming and command-line familiarity help significantly, especially Python and Linux. However, most workshops start with foundational concepts and build progressively. If you can follow tutorials, deploy simple scripts, and stay patient with troubleshooting, you can complete a well-structured AI infrastructure workshop successfully.
Is cloud or on-premise infrastructure better for AI?
Cloud infrastructure suits most teams because it offers instant scalability, low upfront cost, and managed maintenance. On-premise infrastructure makes sense only when you have strict data-control requirements, steady high usage, or compliance rules. Many organizations adopt a hybrid approach, balancing flexibility, cost, and governance based on their workloads.
How long does it take to learn AI infrastructure?
With consistent hands-on practice, you can grasp the fundamentals in a few weeks and reach intermediate proficiency in a few months. Mastery comes from building real systems, breaking and fixing them, and managing live deployments. Working alongside experienced engineers can shorten this timeline considerably.
Why do AI projects fail without good infrastructure?
Many AI projects fail because models cannot move reliably from prototype to production. Without solid infrastructure, teams struggle with reproducibility, scaling, monitoring, and cost control. Good infrastructure provides the automation, observability, and stability needed to keep models accurate, secure, and affordable once real users depend on them.