A clear, expert guide to audio event detection artificial intelligence: how it works, real use cases, model training, benefits, and where the technology is heading next.
Audio Event Detection Artificial Intelligence

Audio event detection artificial intelligence is quietly becoming one of the most practical branches of machine learning. While computer vision dominates headlines, sound carries information that cameras miss entirely: a smoke alarm in an empty house, a gunshot two streets away, a machine bearing that is starting to fail. Systems that can hear and classify these events in real time are now deployed in security, healthcare, manufacturing, and smart homes. This guide explains what the technology actually does, how it works under the hood, and where it delivers measurable value.
After years building data-driven products, I have watched audio AI move from academic novelty to production reliability. The lessons below come from what works in the field, not just what looks good in a research paper.
Quick Answer: Audio event detection artificial intelligence uses machine learning models to automatically identify and label specific sounds, such as alarms, breaking glass, or machinery faults, within an audio stream. It converts sound into spectrograms, extracts features, and classifies events in real time for security, healthcare, and industrial monitoring.
What Is Audio Event Detection?
Audio event detection (AED) is the task of automatically recognizing and time-stamping specific sound events within a continuous audio signal. Unlike speech recognition, which transcribes words, AED identifies non-speech events: a dog barking, a siren, a door slamming, or coughing. The output is typically a label plus a start and end time, so the system knows both what happened and when.
A closely related term is sound event detection (SED), often used interchangeably. The core challenge is that real environments are messy. Multiple sounds overlap, background noise shifts constantly, and the same event, such as a car horn, sounds different across microphones and distances. Modern AI handles this variability far better than the rule-based systems of a decade ago.
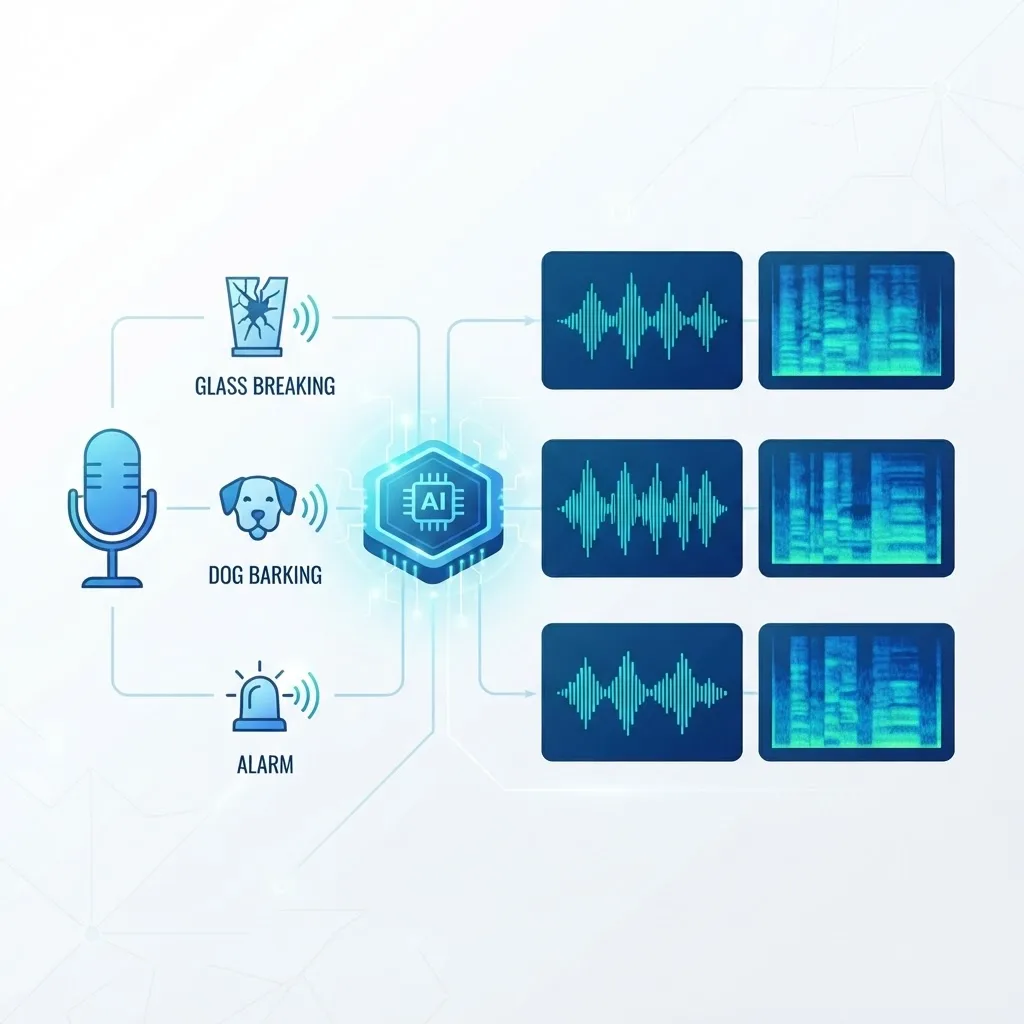
How Audio Event Detection Artificial Intelligence Works
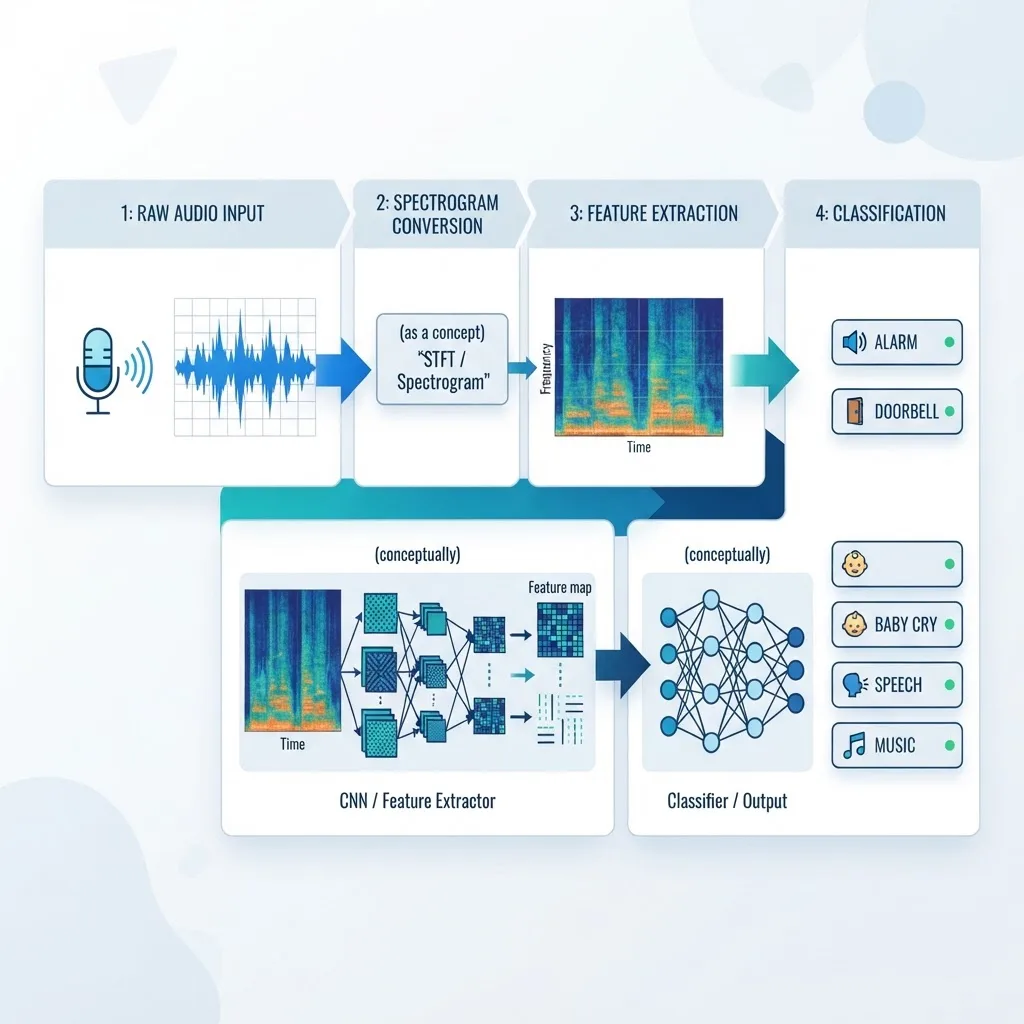
AED works by transforming raw audio into a visual-like representation, extracting patterns, and classifying them with a trained neural network. The pipeline is consistent across most modern systems, and understanding it helps you evaluate any vendor claim.
- Audio capture: A microphone records raw waveform data, usually sampled at 16 kHz or higher.
- Spectrogram conversion: The waveform is converted into a spectrogram, most often a log-mel spectrogram, which maps frequency and intensity over time.
- Feature extraction: A convolutional or transformer-based network learns which frequency patterns correspond to which events.
- Classification and timing: The model outputs event labels with confidence scores and timestamps.
- Post-processing: Thresholds and smoothing reduce false alarms before an alert is triggered.
The spectrogram step is the clever part. By turning sound into an image-like grid, engineers can reuse decades of progress from computer vision. This is why convolutional neural networks (CNNs) originally built for photos work remarkably well on audio.
Why Spectrograms Matter
A spectrogram is a visual chart showing how the frequencies in a sound change over time. Bright regions indicate strong energy at a given pitch and moment. A breaking glass event, for example, produces a sharp burst of high-frequency energy that looks distinct from the low steady hum of an engine. Models learn these visual signatures rather than the raw audio itself.
The Deep Learning Models Behind AED
Modern audio event detection relies heavily on deep learning. According to research published through the DCASE (Detection and Classification of Acoustic Scenes and Events) challenge, which has run annually since 2013, neural network approaches consistently outperform traditional signal-processing methods on real-world datasets.
Three architecture families dominate:
- CNNs (Convolutional Neural Networks): Excellent at spotting local frequency patterns in spectrograms. Fast and efficient.
- CRNNs (Convolutional Recurrent Neural Networks): Add a recurrent layer to model how sounds evolve over time, improving event boundary accuracy.
- Audio Transformers: Models like AST (Audio Spectrogram Transformer) apply attention mechanisms, achieving state-of-the-art accuracy on large datasets such as Google's AudioSet, which contains over 2 million labeled 10-second clips across 632 event classes.
If your organization is exploring custom models like these, specialized artificial intelligence services can shorten the path from prototype to production by handling data pipelines, training, and deployment.
Real-World Use Cases
Audio event detection delivers the most value where sound is a reliable early signal and continuous human listening is impractical. Below are the domains where adoption is strongest today.
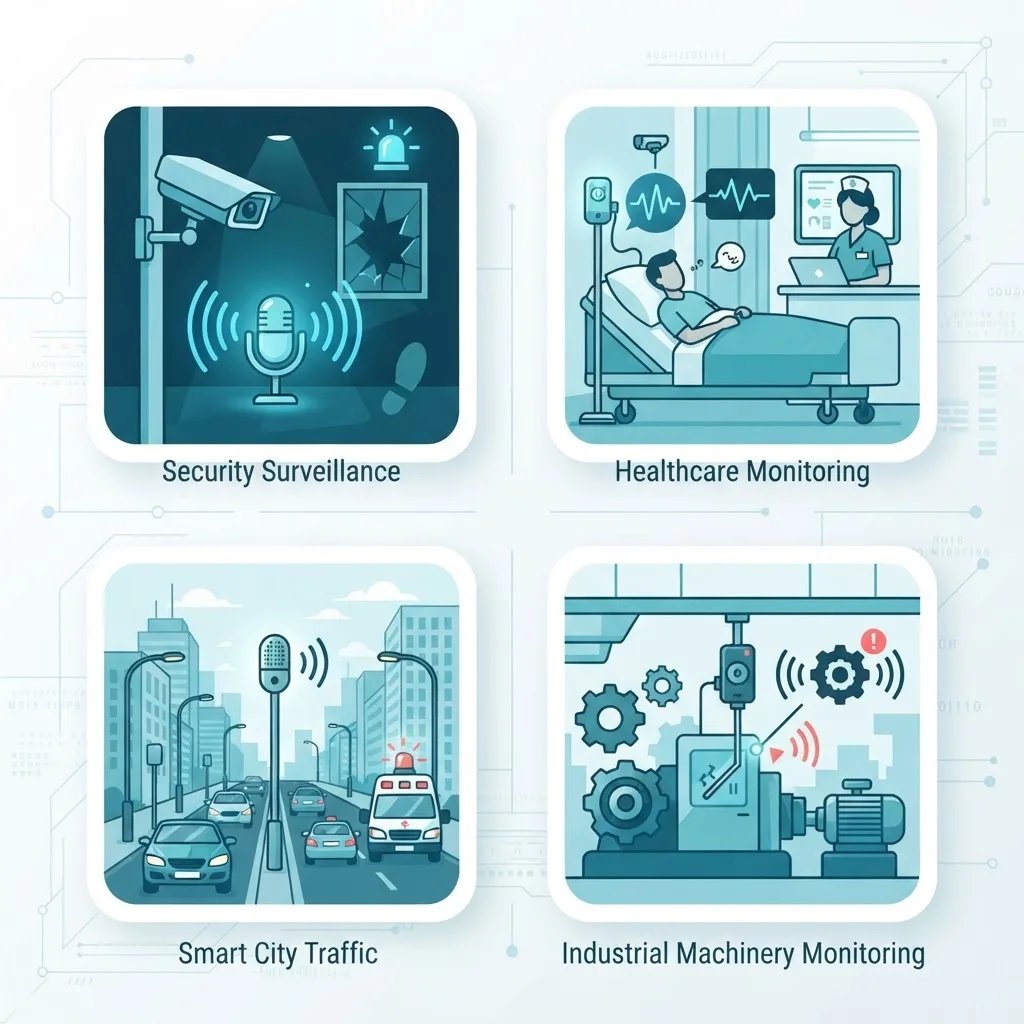
- Security and surveillance: Detecting gunshots, breaking glass, and aggression in public spaces, often faster than a human operator watching dozens of camera feeds.
- Healthcare monitoring: Identifying coughing patterns, falls, or distress sounds in elderly care and remote patient monitoring.
- Industrial predictive maintenance: Recognizing abnormal machine sounds that signal wear before a costly failure occurs.
- Smart cities: Monitoring traffic noise, sirens, and construction to inform urban planning and emergency response.
- Wildlife and environmental research: Counting bird species or detecting illegal logging chainsaws in protected forests.
Smart Home Applications
In smart homes, AED lets a single device respond to sounds that matter for safety. A smart speaker can flag a smoke alarm while you are away, detect a baby crying, or recognize the sound of glass breaking and send an alert. Because these features run on affordable hardware, they represent one of the fastest-growing consumer applications of audio AI.

Comparing AED to Other Audio AI Tasks
Understanding how audio event detection differs from related tasks helps you choose the right tool. The table below breaks down the key distinctions.
| Task | Primary Goal | Output | Common Use |
|---|---|---|---|
| Audio Event Detection | Identify non-speech sounds | Event labels plus timestamps | Security, monitoring |
| Speech Recognition | Transcribe spoken words | Text | Voice assistants |
| Acoustic Scene Classification | Identify the overall environment | Scene label (street, office) | Context awareness |
| Speaker Identification | Recognize who is speaking | Person ID | Authentication |
Many production systems combine several of these. A home security device might run scene classification and event detection together to reduce false alarms, since a "street" scene changes how a loud noise should be interpreted.
How AED Models Are Trained
Training an audio event detection model requires labeled audio data, careful preprocessing, and iterative evaluation. The quality of your labels usually matters more than the sophistication of your model.

A practical training workflow looks like this:
- Collect and label data: Gather recordings of each target event across varied conditions and annotate start and end times.
- Augment the dataset: Add background noise, shift pitch, and mix events to teach the model robustness. This step alone can lift real-world accuracy substantially.
- Convert to spectrograms: Standardize sample rates and generate log-mel spectrograms.
- Train and validate: Use a held-out set to measure precision, recall, and F1 score per event class.
- Deploy and monitor: Track false positives in production and retrain as new edge cases appear.
One field lesson: false positives, not missed events, are what erode user trust. A doorbell system that fires constantly gets unplugged. Tuning confidence thresholds and post-processing is often the difference between a demo and a dependable product.
Benefits and Limitations
The main benefit of AED is continuous, tireless monitoring that scales far beyond human capacity. A single model can watch thousands of audio streams around the clock without fatigue. It also works in darkness, smoke, or around corners where cameras fail.
However, honesty about limits builds trust. Current systems struggle with heavily overlapping sounds, rare events with little training data, and privacy concerns tied to always-on microphones. Edge processing, where audio is analyzed on-device and never uploaded, is emerging as the standard answer to those privacy worries.
The Future of Audio Event Detection
The clearest trend is the move to edge AI, where detection happens directly on small, low-power devices. This reduces latency, protects privacy, and cuts cloud costs. Combined with self-supervised learning, which trains on vast unlabeled audio, models are becoming more accurate with far less manual annotation.

Expect tighter fusion of audio with video and other sensors, giving systems richer context and fewer false alarms. As multimodal AI matures, hearing will become a standard sense for machines rather than a specialized add-on. Businesses building in this space can accelerate development with expert artificial intelligence solutions that cover data, modeling, and deployment end to end.
Key Takeaways
- Audio event detection AI identifies and time-stamps specific non-speech sounds within an audio stream, distinct from speech recognition.
- Spectrograms turn sound into image-like data, letting proven computer vision models classify audio events accurately.
- CNNs, CRNNs, and audio transformers are the dominant architectures, with transformers leading on large datasets like Google's AudioSet (2M+ clips, 632 classes).
- Top use cases include security, healthcare monitoring, predictive maintenance, smart cities, and smart homes.
- False positives, not missed events, are the biggest real-world risk, making threshold tuning essential.
- Edge AI and self-supervised learning are shaping the next generation of private, efficient detection.
For more expert guides on AI and emerging technology, visit ZoneTechify and WebPeak.
Frequently Asked Questions (FAQ)
What is audio event detection in artificial intelligence?
Audio event detection is an AI task that automatically recognizes and time-stamps specific sounds, such as alarms, breaking glass, or machinery faults, within an audio recording. It converts sound into spectrograms, then uses trained neural networks to classify events in real time for monitoring and safety applications.
How is audio event detection different from speech recognition?
Speech recognition transcribes spoken words into text, while audio event detection identifies non-speech sounds like coughs, sirens, or glass breaking. AED also outputs precise start and end times for each event, whereas speech recognition focuses purely on converting language into readable, searchable text.
What machine learning models are used for audio event detection?
The most common models are convolutional neural networks, convolutional recurrent networks, and audio spectrogram transformers. CNNs detect frequency patterns efficiently, CRNNs capture how sounds change over time, and transformers achieve top accuracy on large datasets by using attention to weigh important audio features.
Is audio event detection accurate in noisy environments?
Accuracy in noisy environments has improved significantly through data augmentation and modern architectures. Models trained with realistic background noise and overlapping sounds handle real-world conditions well, though heavily cluttered audio and rare events still challenge current systems and may require additional labeled training data.
What are the main uses of audio event detection AI?
Key uses include security systems that detect gunshots or glass breaking, healthcare tools that monitor coughs and falls, industrial predictive maintenance, smart city noise monitoring, and smart home safety features that recognize alarms or crying. It excels wherever continuous human listening is impractical.
Does audio event detection raise privacy concerns?
Yes, always-on microphones raise valid privacy concerns. The industry is addressing this with edge AI, which processes audio directly on the device so recordings are never uploaded to the cloud. This approach keeps sensitive audio local while still enabling fast, reliable event detection.