A clear, expert guide to threaded artificial intelligence, explaining how multithreading and parallel processing make modern AI models faster, cheaper, and more scalable.
Artificial Intelligence Threaded: How Multithreading Powers Modern AI

Artificial intelligence feels instant, but behind every quick response is a massive amount of computation happening at once. The reason a chatbot answers in seconds instead of minutes is not just a smarter model — it is smarter execution. That execution depends heavily on threading: the practice of splitting work into many concurrent streams so a machine can do many things simultaneously. When people search for "artificial intelligence threaded," they usually want to understand how threads, multithreading, and parallelism actually make AI systems fast and scalable.
This guide breaks that down in plain language, backed by real engineering practice. Whether you are a developer, a product owner, or simply curious, you will leave knowing exactly how threading shapes AI performance and why it matters for your projects. For teams building production AI, the difference between a threaded and single-threaded pipeline can be the difference between a usable product and an abandoned one.
Quick Answer: Threaded artificial intelligence means running AI tasks across multiple concurrent threads so work happens in parallel rather than one step at a time. This multithreading dramatically speeds up data loading, training, and inference, reduces latency, and lets AI systems scale efficiently across modern multi-core CPUs and GPUs.
What Does "Artificial Intelligence Threaded" Actually Mean?

A thread is the smallest unit of execution a processor can manage independently. Multithreading is running several of these threads at the same time within a single program. When we say AI is "threaded," we mean the AI workload has been designed so different parts of the job run concurrently instead of sequentially.
Imagine reading 1,000 documents. A single-threaded approach reads them one after another. A threaded approach hands 250 documents each to four workers who read in parallel, finishing roughly four times faster. AI systems apply this exact logic to data preprocessing, model training, and serving predictions.
This matters because modern hardware is built for parallelism. According to industry benchmarks, consumer CPUs now commonly ship with 8 to 16 cores, and data-center GPUs like NVIDIA's H100 contain tens of thousands of cores. Software that runs on a single thread wastes nearly all of that capacity. Threading is how AI unlocks it. Companies like ZoneTechify and WebPeak build AI solutions specifically to take advantage of this concurrency rather than leaving performance on the table.
Threads vs. Processes vs. Parallelism
These terms are often confused, so here is a clean definition set:
- Thread: A lightweight task that shares memory with other threads in the same process.
- Process: A heavier, isolated program with its own memory space.
- Parallelism: Genuinely executing multiple tasks at the same instant, usually across multiple cores.
- Concurrency: Structuring a program so tasks can make progress independently, even on one core.
AI engineering blends all four. Understanding the distinctions helps you diagnose whether a slow model is bottlenecked by computation, memory, or poor task scheduling.
Why Threading Is Critical for AI Performance

AI workloads are unusually hungry for compute. Training a large language model can involve trillions of operations, and even everyday inference requires billions of calculations per request. Without threading, these operations would run one by one, making real-time AI impossible.
Threading solves three specific bottlenecks:
- Data loading: While the model trains on one batch, worker threads prepare the next batch, so the GPU never sits idle waiting for data.
- Matrix math: Neural networks are built on matrix multiplication, which splits cleanly across thousands of parallel threads.
- Request handling: A production AI API can serve many users at once by threading incoming requests instead of forcing them into a queue.
The payoff is measurable. Google has repeatedly noted that 53% of mobile users abandon a site that takes longer than three seconds to load, and the same impatience applies to AI features. Threaded execution is often the only way to keep response times inside that critical window.
The Cost of Ignoring Threading
A single-threaded AI service running on a 16-core machine might use just 6% of available compute. That is not only slow — it is expensive, because you pay for hardware you never use. Efficient threading can cut cloud bills significantly by extracting full value from every core you rent.
How Threaded AI Processing Works Step by Step
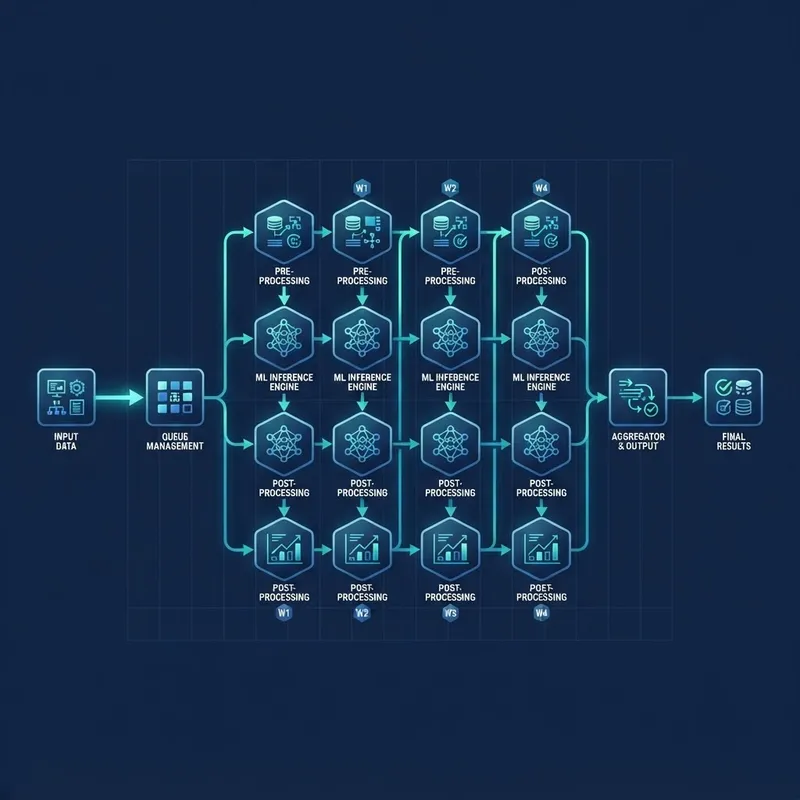
Here is how a well-designed threaded AI pipeline typically flows:
- Ingestion: Incoming data or requests are received by a main thread.
- Dispatch: A scheduler distributes work across a pool of worker threads.
- Parallel compute: Each worker handles its slice — tokenizing text, loading images, or running matrix operations.
- Synchronization: Results are collected and combined once all workers finish their portion.
- Response: The final output is returned to the user or written to storage.
The key skill is synchronization — making sure threads do not corrupt shared data when they write at the same time. Poorly synchronized threads cause race conditions, where the outcome depends on unpredictable timing. Experienced engineers use locks, queues, and immutable data structures to keep threaded AI both fast and correct.
Threaded vs. Single-Threaded AI: A Direct Comparison
The table below summarizes the practical differences engineers weigh when architecting AI systems.
| Factor | Single-Threaded AI | Threaded AI |
|---|---|---|
| Speed | Slow, sequential | Fast, parallel |
| Hardware use | Uses one core | Uses all cores/GPU |
| Latency under load | High, requests queue | Low, requests overlap |
| Scalability | Limited | Scales with cores |
| Complexity | Simple to build | Requires careful sync |
| Cost efficiency | Poor | Strong |
Single-threaded code is easier to write and debug, which is why prototypes often start there. But any AI product expected to serve real users at scale must move to a threaded or fully parallel architecture. Teams offering AI development services treat this transition as a core part of shipping production-ready models.
Parallel Computing: Threading at Scale

Threading on a single CPU is powerful, but AI truly scales through parallel computing on GPUs and distributed clusters. A GPU is essentially a threading machine: it runs thousands of small threads at once, which is exactly what neural network math demands.
When one GPU is not enough, engineers use distributed training, spreading a model across many machines that coordinate over a network. Techniques like data parallelism (splitting the dataset) and model parallelism (splitting the model itself) are threading concepts applied at a massive scale. This is how frontier models are trained on thousands of GPUs working in concert.
The practical lesson is that threading is not a single trick — it is a mindset that scales from a single laptop core up to an entire data center.
Real-World Benefits of Threaded AI

Threading is not an abstract engineering detail; it produces outcomes users feel directly:
- Faster responses: Chatbots, search, and recommendations return results in real time.
- Higher throughput: One server can handle far more simultaneous users.
- Lower costs: Full hardware utilization means fewer machines for the same workload.
- Better user experience: Reduced latency keeps people engaged instead of frustrated.
- Room to grow: Threaded systems scale as demand rises without a full rebuild.
These benefits compound. A threaded pipeline that is twice as efficient can effectively halve infrastructure spend while doubling capacity — a rare win in engineering where speed and cost usually trade off against each other.
Implementing Threaded AI: Practical Guidance

If you are building threaded AI, keep these expert-tested principles in mind:
- Profile before optimizing. Measure where time is actually spent; do not guess. Often data loading, not the model, is the bottleneck.
- Use thread pools. Reusing a fixed set of worker threads avoids the overhead of constantly creating and destroying them.
- Mind the language. Some runtimes, like standard Python, have a Global Interpreter Lock (GIL) that limits pure-Python threading, so heavy math is offloaded to libraries written in C or CUDA that release it.
- Prefer immutable data. Data that never changes cannot be corrupted by concurrent access, eliminating whole classes of bugs.
- Batch requests. Grouping small requests into batches lets the hardware process them together far more efficiently.
Good threading is as much about design discipline as raw coding. The safest threaded systems are those with clear ownership of data and minimal shared mutable state.
The Future of Threaded Artificial Intelligence

Threading in AI is becoming more automatic and more powerful. Modern frameworks increasingly handle thread scheduling for developers, and specialized AI chips are being designed with even more parallel units. As models grow, the ability to spread work efficiently across threads, cores, and machines will only become more central.
The next frontier is intelligent scheduling — systems that decide in real time how to distribute work based on current load, hardware, and priority. This adaptive threading will make AI faster and greener by wasting less energy on idle hardware. For businesses, the takeaway is clear: efficient concurrency is no longer optional, it is a competitive advantage.
Key Takeaways
- Threaded AI runs tasks concurrently instead of sequentially, dramatically improving speed and scalability.
- Modern CPUs commonly have 8–16 cores and data-center GPUs hold tens of thousands of cores — threading is what actually uses them.
- Google reports 53% of mobile users abandon slow experiences after three seconds, making low latency essential for AI features.
- Threading benefits data loading, matrix math, and request handling, the three biggest AI bottlenecks.
- GPUs and distributed training extend threading to massive scale through data and model parallelism.
- Proper synchronization prevents race conditions and keeps threaded AI both fast and correct.
Frequently Asked Questions (FAQ)
What does threaded mean in artificial intelligence?
Threaded artificial intelligence means the AI workload is split into multiple threads that run concurrently instead of one step at a time. This multithreading lets a processor handle data loading, calculations, and requests in parallel, which makes AI systems significantly faster, more responsive, and more efficient at using hardware.
Why is multithreading important for AI?
Multithreading is important because AI involves billions of calculations that would be far too slow if run sequentially. By spreading work across many threads and cores, AI systems reduce latency, serve more users at once, and fully use modern CPUs and GPUs, lowering costs while delivering real-time performance.
Is threaded AI the same as parallel computing?
They are closely related but not identical. Threading structures a program so tasks run concurrently, while parallel computing genuinely executes multiple tasks at the same instant across many cores or GPUs. In practice, threaded AI uses parallel computing to scale from a single processor up to large distributed clusters.
Does Python threading work well for AI?
Standard Python has a Global Interpreter Lock that limits pure-Python threading for heavy computation. However, AI libraries like PyTorch and TensorFlow offload math to optimized C and CUDA code that releases the lock, so Python still runs highly threaded, parallel AI workloads efficiently in real production systems.
How does threading reduce AI costs?
Threading reduces costs by fully using the hardware you already pay for. A single-threaded service may use a small fraction of a multi-core machine, wasting money. Threaded execution keeps every core busy, so you need fewer servers to handle the same workload, cutting cloud infrastructure bills substantially.
Can any AI model be made threaded?
Most AI models can benefit from threading, especially in data loading and inference, but the degree varies. Tasks that split cleanly, like matrix math or batch processing, parallelize well. Some sequential steps resist threading, so engineers profile each workload to apply concurrency where it delivers the biggest speed gains.